
Introduction
Nowadays, AI is boom in the market. This AI field touches every sector like financial domain, medical domain or any domain where some history data is available to make some kind of intelligence. Today lots of internet based devices are there and those are generating huge amount of data and patterns, these data is the new oil in today’s environment to make some artificial intelligence. Everyone is looking for a some kind of Bot or assistant that can help in customer support without much help of human. For any AI assistant good training data is the oil for it to perform well. Today, lots of big models are available in market like OpenAI, Hugging Face, Mistral, llama etc. Some are paid and some are open source. Such models are highly trained on lot of data and parameters, those are capable of answering lot of user queries precisely.
Here, we will see in this blog post how to use LangChain framework to make LLM (Large Language Model) based application.
What is LangChain
LangChain is a framework that can be used to make LLM based applications. This framework is so useful and powerful that we can create applications with almost all LLM models availbale in the market. Like, we can create application with OpenAI, llama, Mistral and many more models available in it’s documentation. So, langchain is a single interface that can interact with any model.
Features of LangChain
– Single interface for developing LLM based applications with many LLM models
– Useful functions:
Below are the core features and functions of this framework, these are very useful in developing LLM application.
a. Load data from any source
Here, you can load data from csv file, text file, pdf, URL, json and many more other ways. Many useful class and functions are available to load data from many sources.
b. Split data in desired manner
Splitting data is also important function when we have large amount of text data. Here we can split data into chunks of desired number of characters. These split documents are useful to create vector database.
c. Generate Vector Database
Once we split the data we can generate vector database for the above loaded data. This vector database is the numerical representation of chunks (split data)
d. Store in local such Vector Database
Once we have generated vector data that can be stored into local disk as well. That way we can access locally the generated database and no need to create such data every time.
e. Load local Vector Database and query to get similar looking vectors
So, finally we can load our stored database in code and perform user query to get similar results (can return similar looking vectors)
Practical Use Cases for LLM Applications
Below are some use cases that can be served as LLM applications,
a. HR Virtual Assistant:
Here you can provide entire HR policy in PDF format to generate local Vector Database for your company and connect this database to LLM like OpenAI for answering user queries.
This intelligence you can provide in terms of your company’s local chat bot. So every employee can query for questions like,
– How many casual leaves I can take in a year
– Total how much sick leaves are allotted to every employee
– what is the salary day
– what is increment cycle and what parameters are measured for it for better growth
– What is exit policy
– what is the notice period to serve
b. Blog or Document Summarize:
Here you can summarize long document, that way you can have quick overview about the document and you can save your reading time.
c. Talk to your Database:
Here we can talk to our relational databases, no need to make SQL query to database. For example you can ask how many total employees are there in company, How many balck T-shitrs are remaining in store of size medium. The LLM application automatically perform query in respective database table to answer your question.
Useful Components of LangChain
Here are some useful concepts of LangChain those are helpful in developing LLM applications.
a. LLM:
LLM is the component for large language model, here model can be anyone like OpenAI, MistralAI etc. This component can take input string and can return generative AI output. For example you asked “tell me funny joke on bear” and it will return a relative joke on bear in string format.
b. Prompt:
Prompt is like a input string with variables. This input string you can pass to LLM component. So every time you can pass different variables in input string and generate desired response.
c. Parser:
There are different kind of parsers available, it helps to parse the output we get from LLM. This will return main output string in response.
d. Chain:
Chain is combination of, prompt | llm | parser. By combining these components you can create a chain that is invoke-able component. You can pass various input string with variables mentioned in prompt, and can get desired response.
e. Retriever:
Retriever component is generated from the vector database and this is useful in creating RAG (Retrieval-Augmented Generation) chain. With the help of retriever you can use and query to your custom local model (Your specific knowledge base) and can ask LLM model (OpenAI model) to make appropriate output based on retrieved response from custom local model. It is like to tell your LLM model, Hey! generate me response for my query based on my specific knowledge base.
Installation
Here are the required packages we need to install in virtual environment. First create virtual environment.
cd /home/to_your_project_folder python3 -m venv .venv source .venv/bin/activate
Now you entered into virtual environment, install below packages in it. In my next article I have given requirement.txt file, it is better to use that file for installing the required packages rather than individual package installation. You will find the command to install from requirement.txt file at https://telephonyhub.in/2024/07/29/host-langchain-apis-with-flask/
pip3 install bs4 pip3 install faiss-cpu pip3 install fastapi pip3 install langchain pip3 install langchain-community pip3 install langchain-mistralai pip3 install langchain-openai pip3 install langserve[all] pip3 install mysql-connector-python pip3 install pypdf pip3 install python-dotenv pip3 install scikit-learn pip3 install sentence-transformers curl -fsSL https://ollama.com/install.sh | sh ollama pull gemma:2b ollama pull llama3.1
In this guide we are using OpenAI and Mistral AI for our examples. So, we need to take API keys from both the providers. Also get one key from LangSmith for debug purposes.
As per shown in below screen shot you can signup to OpenAI and generate API key for it.
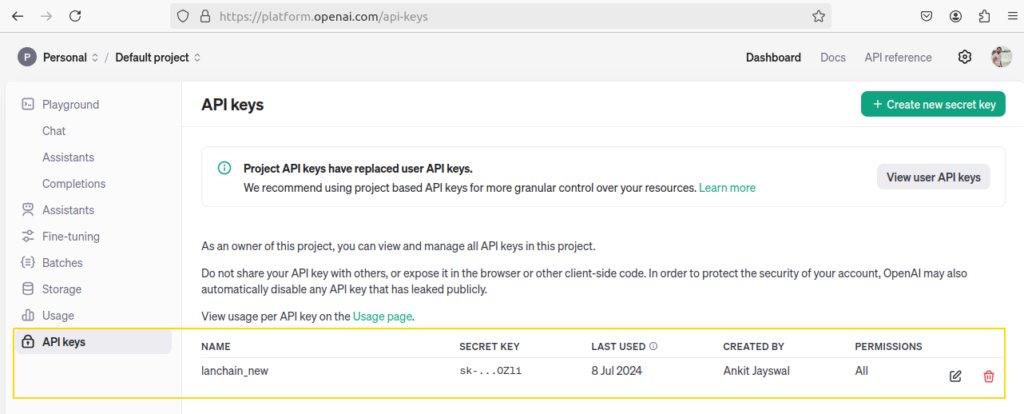
Now, as per shown in below screen shot you can get API key from Mistral AI also to use. Just signup in Mistral AI and generate key.
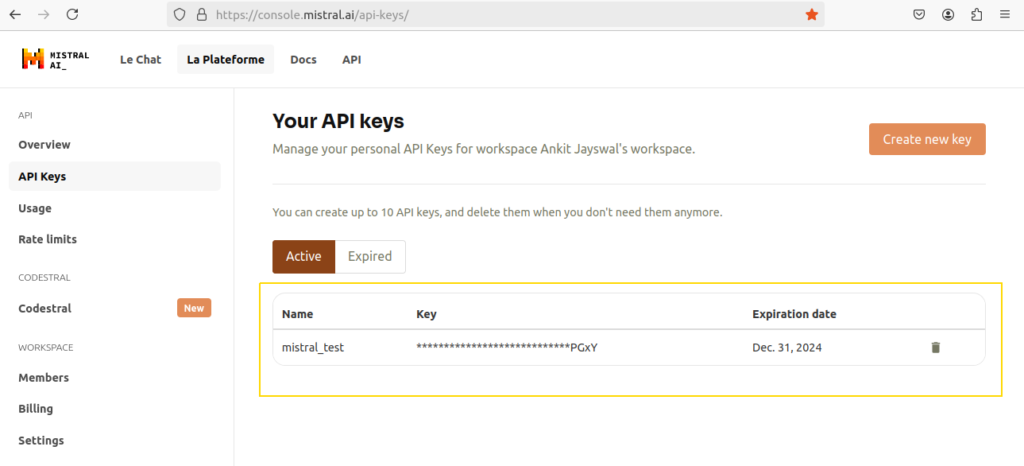
If we want to debug our requests performed in applications we can signup into LangSmith account and create API key. As per below screen shot you can create api key.
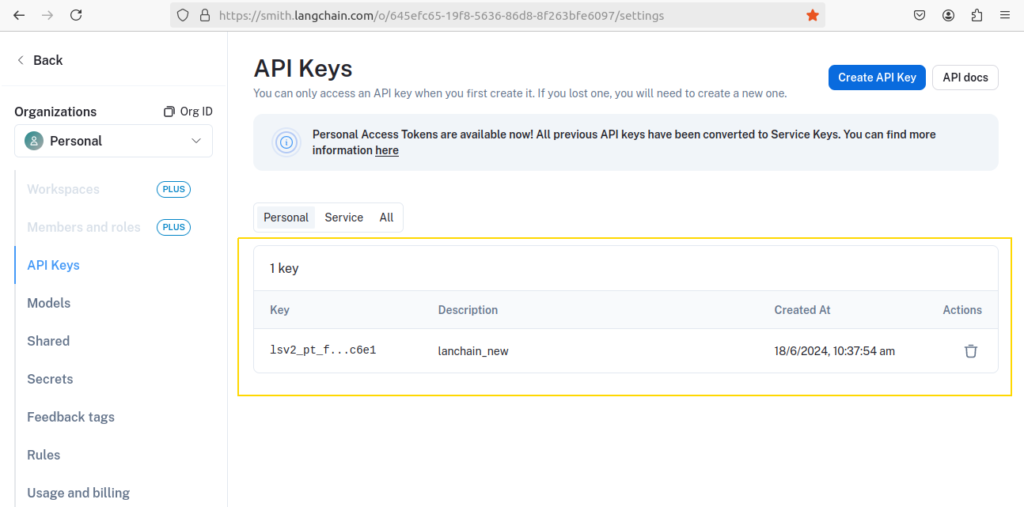
Ok, now once we have above API keys we are good to go ahead with our examples. Now first create .env file in your project environment folder and add required keys as show below.
cd /home/path_to_your_project_folder vim .env
OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" LANGCHAIN_API_KEY="lsv2_xxxxxxxxxxxxxxxxxxxxxxxxxxxxx" MISTRAL_API_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
Add above keys into .env file and save it. Replace here with your keys. Now we can load these keys in our code examples with environment variables. Let’s see very first example code of LLM application.
Example1 – Simple LLM application
Here in below example we made a simple llm call to OpenAI model and printing response came from it.
Example Code:
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import ChatOpenAI
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
model = ChatOpenAI()
response = model.invoke("tell me three lines about Rashmika Mandanna")
print(response.content)
Output from above example code
1. Rashmika Mandanna is an Indian actress who primarily works in Telugu and Kannada films. 2. She gained popularity for her performances in movies like Geetha Govindam and Dear Comrade. 3. Rashmika Mandanna is known for her charming screen presence and versatile acting skills.
Example2 – Prompt Model and Parser example
Here, we are creating simple chain by combining prompt, model and parser components. Combining these elements will create one chain which can be called with defined input variables in prompt as shown in below example. Here {country} and {category} are the variables, that we can pass during calling of chain.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
template = "I want to open {country} {category} company, please suggest me 3 best names for it"
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
parser = StrOutputParser()
chain = prompt | model | parser
response = chain.invoke({"country":"Indian","category":"tech"})
print(response)
Output from above example code
1. TechIndia Innovations 2. BharatTech Solutions 3. DesiTech Creations
Example3 – LLM Call with Structured Output
Sometimes we need the output in some meaningful structure like JSON. So here in this example we will see how we can get the json response with provided json schema. In below example ‘game’, ‘player’, ‘score’ are the json keys which holds the answer of our query.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
model = ChatOpenAI(model="gpt-3.5-turbo-0125")
json_schema = {
"title": "Sports",
"description": "Get highest score of player",
"type": "object",
"properties": {
"game": {
"type": "string",
"description": "The sport in sentence",
},
"player": {
"type": "string",
"description": "The player in the sport",
},
"score": {
"type": "integer",
"description": "How many runs scored by player",
},
},
"required": ["game", "player","score"],
}
structured_model = model.with_structured_output(json_schema)
data = structured_model.invoke("let me know the highest runs of Sachin Tendulkar in cricket in ODI")
print(data)
#print(data['game'])
#print(data['player'])
#print(data['score'])
Output from above example code
{'game': 'cricket', 'player': 'Sachin Tendulkar', 'score': 200}
Example4 – Entity Detection LLM Call
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_mistralai import ChatMistralAI
from langchain_openai import ChatOpenAI
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["MISTRAL_API_KEY"] = os.getenv('MISTRAL_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
class Person(BaseModel):
"""Information about a person."""
name: str = Field(default=None, description="The name of the person")
hair_color: str = Field(
default=None, description="The color of the person's hair if known"
)
height_in_meters: str = Field(
default=None, description="Height measured in meters"
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert extraction algorithm. "
"Only extract relevant information from the text. "
"If you do not know the value of an attribute asked to extract, "
"return null for the attribute's value.",
),
# Please see the how-to about improving performance with
# reference examples.
# MessagesPlaceholder('examples'),
("human", "{text}"),
]
)
llm = ChatMistralAI(model="mistral-large-latest", temperature=0)
runnable = prompt | llm.with_structured_output(schema=Person)
text = "Ankit is 5 feet and 8 inch tall and has black hair."
data = runnable.invoke({"text": text})
print(data)
Output from above example code
name='Ankit' hair_color='black' height_in_meters='1.7272'
Example5 – Classification LLM Call
Here, we are classifying user query in terms of ‘sentiment’, ‘aggressiveness’ and ‘language’. The Classification class with BaseModel is used here and we described the required classification parameters with it’s description.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_mistralai import ChatMistralAI
from langchain_openai import ChatOpenAI
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
tagging_prompt = ChatPromptTemplate.from_template(
"""
Extract the desired information from the following passage.
Only extract the properties mentioned in the 'Classification' function.
Passage:
{input}
"""
)
class Classification(BaseModel):
sentiment: str = Field(description="The sentiment of the text")
aggressiveness: int = Field(
description="How aggressive the text is on a scale from 1 to 10"
)
language: str = Field(description="The language the text is written in")
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0125").with_structured_output(
Classification
)
tagging_chain = tagging_prompt | llm
inp = "Hill station was so good, I love it"
inp = "I told the same thing two times but you are not getting my concern"
inp = "This is fifth time I am calling in your customer support, still I did not get the soulution of cable TV channels"
res = tagging_chain.invoke({"input": inp})
print(res)
Output from above example code
sentiment='positive' aggressiveness=2 language='english' sentiment='neutral' aggressiveness=5 language='English' sentiment='negative' aggressiveness=5 language='English'
Example6 – Store Vector Database on local Disk
In this example we will load text data from our .txt file. This text file ‘openai_test_data.txt’ file has some information available in it. I will provide that text data below so you can create the text file at your side also. So, idea here is to generate and save vector database on local disk and that we can access later for user queries.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
# Load the document
raw_documents = TextLoader('openai_test_data.txt').load()
# Split the document
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=20,length_function=len,is_separator_regex=False,)
documents = text_splitter.split_documents(raw_documents)
embeddings = OpenAIEmbeddings()
# SAVE VECTOR DATA TO LOCAL DISK - ONE TIME
vector_data = FAISS.from_documents(documents, embeddings)
file_path = "openai_vector_data"
vector_data.save_local(file_path)
Example txt file
Below text data you can copy paste into one file named ‘openai_test_data.txt’ , and save it. So you can load the file in above code.
Hey, I am Ankit Jayswal who wrote articles in the field of VOIP and AI. He has website to show case these blogs. The website name is https://telephonyhub.in , you can visit this site for more information. This website has very interesting blog about voice bot, voice bot is the assistant that can answer your questions on voice call. There are many reasons for choosing CPaaS solution. Many telecom companies and call center providers are adopting this solution as it is deployed in highly scalable environment. In this solution one can expose his/her VoIP services in form of API and web hook responses only. This solution provides programmable interface to develop the IVR call flows, now no need to develop dialplan every time for a new IVR. The all heavy lifting is done in core development. People just need to Buy DID number, configure with incoming URL and generate appropriate web hook response to drive the call. Also, some of the services can be delivered in form of APIs. This way customers do not require to worry about heavy VoIP server setup and it’s maintenance. They just need to hit required API to consume the service. As this solution is API rich, one can develop his/her own UI to present it to other clients. Benefits of CPaaS Solution: – Telecom companies can offer their voice services in form of API and that way they can expose their services in more effective way – Customer does not require to do heavy VoIP server setup – Telecom companies do not require to route physical SIP trunk lines to customer premises – Customers do not require to care about server administration, any down time or scaling the voice traffic About my CPaaS Solution: I have developed such solution which is based on Asterisk media server, and Kamailio for scaling the voice traffic. In my solution there is one Programmable Voice Interface and one is API Interface. About both the interfaces I have given detailed explanation as below. Programmable Voice Interface (INBOUND): This interface provides you flexibility to develop your own IVR, Voicebot flow programmatically. You can use any programming language and generate appropriate web hook response as below. I have given some example apps that you can generate to create Voicebot or IVR. API Based Interface (OUTBOUND): This is just API request, that is only required to hit with API credentials to use it. Here account wise separate API credentials are provided to consume the services and log data account wise.
Output from above example code
Once you run above code, you will notice one folder called ‘openai_vector_data’ will be created. And inside that folder two files called ‘index.faiss’ and ‘index.pkl’ will be created.
Example7 – Load Vector Database From local Disk
In Example6 we generated and stored vector database, now in this example we will load that database and use it. Here we will use retriever component to query our vector database and show results in output. You will see we got answers in the context of data mentioned in our text file only.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
embeddings = OpenAIEmbeddings()
# LOAD VECTOR DATA FROM THE SAVED DATA ON DISK
vector_data = FAISS.load_local("openai_vector_data",embeddings,allow_dangerous_deserialization=True)
retriever = vector_data.as_retriever(search_type="similarity",search_kwargs={"k": 1},)
data = retriever.batch(["what is CPaaS solution", "who is ankit jayswal"])
print("ANSWER1-----")
print(data[0][0].page_content)
print(data[0][0].metadata)
print("\n###################################################################\n")
print("ANSWER2-----")
print(data[1][0].page_content)
print(data[1][0].metadata)
Output from above code
ANSWER1-----
Benefits of CPaaS Solution:
– Telecom companies can offer their voice services in form of API and that way they can expose their services in more effective way
– Customer does not require to do heavy VoIP server setup
– Telecom companies do not require to route physical SIP trunk lines to customer premises
– Customers do not require to care about server administration, any down time or scaling the voice traffic
About my CPaaS Solution:
{'source': 'openai_test_data.txt'}
###################################################################
ANSWER2-----
Hey, I am Ankit Jayswal who wrote articles in the field of VOIP and AI. He has website to show case these blogs. The website name is https://telephonyhub.in , you can visit this site for more information. This website has very interesting blog about voice bot, voice bot is the assistant that can answer your questions on voice call.
{'source': 'openai_test_data.txt'}
Example8 – RAG (Retrieval Augmented Generation) Understanding
In this example we will see how we can use some external knowledge base to generate response through LLM. In some cases it is possible that we do not rely on public data or we do not get proper answer from publicly available knowledge base. In such cases we can use our some private knowledge base and say the LLM model to look into this particular knowledge base and give me response based on that base. This way we can use our own knowledge base and reply to user query in more effective way and prepare appropriate response with power of LLM. Below in example you will notice we made two LLM calls, the first one is direct llm call and second llm call is using external knowledge to give answer. In output below you can see the difference between two calls, we get different outputs. Here, info for the user query about “Ankit Jayswal” , may not be publicly available as he might not much famous person but if we have custom knowledge base then we can have proper answer about him with power of LLM to craft it properly.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
embeddings = OpenAIEmbeddings()
# LOAD VECTOR DATA FROM SAVED DATA ON DISK
vector_data = FAISS.load_local("openai_vector_data",embeddings,allow_dangerous_deserialization=True)
retriever = vector_data.as_retriever(search_type="similarity",search_kwargs={"k": 1},)
template = """
Answer this question using the provided context only.
{question}
Context:
{context}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
rag_chain = {"context":retriever,"question":RunnablePassthrough()} | prompt | llm
response = rag_chain.invoke("let me know about ankit jayswal")
print("##### RESPONSE FROM DIRECT LLM CALL ####")
print(llm.invoke("who is Ankit Jayswal").content)
print("\n")
print("#### RESPONSE FROM EXTERNAL KNOWLEDGE BASE ####")
print(response.content)
Output from above code
##### RESPONSE FROM DIRECT LLM CALL #### There is not enough information available to determine who Ankit Jayswal is. It is possible that he is a private individual or a public figure with limited online presence. #### RESPONSE FROM EXTERNAL KNOWLEDGE BASE #### Ankit Jayswal is a writer who has written articles in the field of VOIP and AI. He has a website called https://telephonyhub.in where he showcases his blogs. The website contains interesting blogs about voice bots, which are assistants that can answer questions on voice calls.
Example9 – Ask to your PDF file
Here, in this example we will load one PDF file and then create retriever object of that particular PDF file. Now, this retriever object will have all knowledge of the PDF file and that we can use to answer user queries. Finally we will create one chain with this retriever and invoke that chain to answer user queries. Here, I asked about “benefits of chatbot” and I got appropriate output response from PDF file as show below.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_community.document_loaders import PyPDFLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_core.output_parsers import StrOutputParser
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
loader = PyPDFLoader("BuildingChatBotsWithTwilio.pdf")
pages = loader.load_and_split()
#print(pages)
embeddings = OpenAIEmbeddings()
template = """
Answer this question using the provided context only.
{question}
Context:
{context}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
parser = StrOutputParser()
vector_data = FAISS.from_documents(pages, embeddings)
retriever = vector_data.as_retriever(search_type="similarity",search_kwargs={"k": 1},)
chain = {"context":retriever,"question":RunnablePassthrough()} | prompt | model | parser
response = chain.invoke("benefits of chatbot")
print(response)
Output from above code
The benefits of chatbots include instant customer support, 24/7 availability, reducing agent's workload, and filtered traffic reaching actual agents.
Example10 – Summarize the Article
Sometimes we may require to summarize long content to understand it quickly and to have overview from large data. This way we can save out time instead of reading entire content. Here, in this example we will use web loader to load our blog data from URL and we will summarize the content available on that particular page. In this example below I have put one of my own blog URL to summarize that page.
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from bs4 import BeautifulSoup
from langchain.chains.summarize import load_summarize_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["MISTRAL_API_KEY"] = os.getenv('MISTRAL_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
loader = WebBaseLoader("https://telephonyhub.in/2023/01/13/how-to-make-auto-dialer-with-asterisk/")
docs = loader.load()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
result = chain.invoke(docs)
print(result["output_text"])
Output from above code
The article provides a detailed guide on how to create an auto dialer using Asterisk, a popular open-source PBX. It explains the importance of auto dialers in call centers, the process of creating call files, and setting up the dial plan in Asterisk's extensions.conf file. It also includes a sample Python code for generating and processing call files. The article aims to help readers build their own custom auto dialer software.
Example11 – Ask your Database in natural language
In this example we will see feature of talking to MySql database in natural language. Generally, we have to make SQL query to retrieve certain information from database. But here you can directly talk to your database in human natural language. For example, you can ask “How many employees are there in organisation”, “How many black t-shirts are remaining of size medium in the store”. For such phrases the LLM will make sql query by itself and returns you the result.
For example we asked below two questions in the code:
1. who is youngest employee in company
2. how many white t shirts are availbale in the store of size medium and of round neck type
For both the queries in human language are being answered by the AI agent correcly. Here it automatically detects the age parameter to find out youngest employee. Also it returns correct number of white t_shirts available of size medium and round neck type. So, this is the beauty of the feature, you can ask to database just like you are asking to human.
Here I assume you have MySql is installed in your local. First goto your mysql prompt and Create one mysql database called “store” and create two tables called “company_employee” and “t_shirts”.
CREATE DATABASE store; use store; CREATE TABLE `company_employee` ( `employee_id` int NOT NULL AUTO_INCREMENT, `first_name` varchar(255) NOT NULL, `last_name` varchar(255) DEFAULT NULL, `age` int DEFAULT NULL, PRIMARY KEY (`employee_id`) ); CREATE TABLE `t_shirts` ( `product_id` int NOT NULL AUTO_INCREMENT, `colour` varchar(255) NOT NULL, `size` varchar(255) DEFAULT NULL, `type` varchar(255) DEFAULT NULL, PRIMARY KEY (`product_id`) );
Then add some sample records in it with help of below queries,
insert into company_employee (first_name,last_name,age) values ('ramesh','jain',37);
insert into company_employee (first_name,last_name,age) values ('uday','patel',36);
insert into company_employee (first_name,last_name,age) values ('nisha','patel',35);
insert into t_shirts (colour,size,type) values ('black','medium','round_neck');
insert into t_shirts (colour,size,type) values ('black','small','round_neck');
insert into t_shirts (colour,size,type) values ('black','large','round_neck');
insert into t_shirts (colour,size,type) values ('black','medium','round_neck');
insert into t_shirts (colour,size,type) values ('white','large','round_neck');
insert into t_shirts (colour,size,type) values ('white','large','round_neck');
insert into t_shirts (colour,size,type) values ('white','medium','round_neck');
insert into t_shirts (colour,size,type) values ('white','small','round_neck');
insert into t_shirts (colour,size,type) values ('white','small','v_neck');
insert into t_shirts (colour,size,type) values ('white','medium','v_neck');
insert into t_shirts (colour,size,type) values ('white','large','v_neck');
Example Code
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_community.utilities import SQLDatabase
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.agent_toolkits import create_sql_agent
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')
os.environ["MISTRAL_API_KEY"] = os.getenv('MISTRAL_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('LANGCHAIN_API_KEY')
# database connection
mysql_uri = 'mysql+mysqlconnector://admin:LenArWXwm3fcVSfX@localhost:3306/store'
db = SQLDatabase.from_uri(mysql_uri)
# prompt template to give description about database and database tables
template = """You are an expert AI assistant who answers user queries from looking into the mysql database called store.
The store database has following tables:
company_employee,t_shirts
The company_employee table has following fields:
first_name,last_name,age
The t_shirts table has following fields:
colour,size,type
Please answer for below user_query:
{user_query}
"""
prompt_template = ChatPromptTemplate.from_template(template)
# OpenAI LLM object
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# creating sql agent to serve user queries
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
user_query = "who is youngest employee in company"
user_query = "how many white t shirts are availbale in the store of size medium and of round neck type"
response = agent_executor.run(prompt_template.format_prompt(user_query=user_query))
print("#################### ANSWER #########################")
print("ANSWER: "+response)
Output from above code
#################### ANSWER ######################### ANSWER: The youngest employee in the company is Nisha Patel, who is 35 years old. #################### ANSWER ######################### ANSWER: There are 3 white t-shirts available in the store that are of size medium and of round neck type.
Here is my github link where you can see some more examples, https://github.com/ankitjayswal87/LangChainLLM
I hope you find this article useful, you can connect me for this kind of solutions for your own use cases. Happy to help you and learn some thing new! Thanks!